Le buffer overflow (dépassement de tampon)
Qu'est-ce qu'un buffer overflow ?
Un buffer overflow est une attaque très efficace et assez compliquée à réaliser. Elle vise à exploiter une faille, une faiblesse dans une application (navigateur, logiciel de mail, etc...) pour exécuter un code arbitraire qui compromettra la cible (acquisition des droits administrateur, etc...).
Faire planter pour exécuter du code
Le fonctionnement général d'un buffer overflow est de faire crasher un programme en écrivant dans un buffer plus de données qu'il ne peut en contenir (un buffer est un zone mémoire temporaire utilisée par une application), dans le but d'écraser des parties du code de l'application et d'injecter des données utiles pour exploiter le crash de l'application.
Cela permet donc en résumé d'exécuter du code arbitraire sur la machine où tourne l'application vulnérable.
L'intérêt de ce type d'attaque est qu'il ne nécessite pas -le plus souvent- d'accès au système, ou dans le cas contraire, un accès restreint suffit. Il s'agit donc d'une attaque redoutable. D'un autre côté, il reste difficile à mettre en oeuvre car il requiert des connaissances avancées en programmation; de plus, bien que les nouvelles failles soient largement publiées sur le web, les codes ne sont pas ou peu portables. Une attaque par buffer overflow signifie en général que l'on a affaire à des attaquants doués plutôt qu'à des "script kiddies".
Techniquement, comment fonctionne un buffer overflow ?
Le problème réside dans le fait que l'application crashe plutôt que de gérer l'accès illégal à la mémoire qui a été fait. Elle essaye en fait d'accéder (lire, exécuter) à des données qui ne lui appartiennent pas puisque le buffer overflow a décalé la portion de mémoire utile à l'application, ce qui a pour effet (très rapidement) de la faire planter.
D'un point de vue plus technique, la pile (stack en anglais) est une partie de la mémoire utilisée par l'application pour stocker ses variables locales. Nous allons utiliser l'exemple d'une architecture Intel (32 bits). Lors d'un appel à une sous-routine, le programme empile (push) le pointeur d'instruction (EIP) sur la pile (stack) et saute au code de la sous-routine pour l'exécuter. Après l'exécution, le programme dépile (pop) le pointer d'instruction et retourne juste après l'endroit où a été appelée la sous-routine, grâce à la valeur d'EIP. En effet, comme EIP pointe toujours vers l'instruction suivante, lors de l'appel de la sous-routine il pointait déjà vers l'instruction suivante, autrement dit l'instruction à exécuter après la sous-routine (= adresse de retour).
D'autre part, lors de l'appel de la sous-routine, celle-ci va dans la majorité des cas créer sa propre pile dans la pile (pour éviter de gérer des adresses compliquées). Pour cela elle va empiler la valeur de la base de la pile (EBP) et affecter la valeur du pointeur de pile (ESP) à celle de la base (EBP).
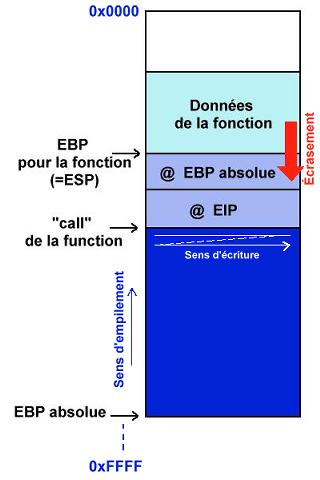
- ESP est le pointeur du sommet de la pile.
- EBP est le pointeur de la base de la pile.
- EIP est le pointeur de la prochaine instruction à exécuter. Il pointe donc toujours une exécution en avance.
En résumé, on sauvegarde la valeur originale de la base et on décale le tout ensuite. Lors du retour de la sous-routine, on dépile EBP et réaffecte sa valeur originale pour restaurer la pile initiale.
Voici pour le déroulement "normal" des opérations. Un point intéressant à citer est le fait que dans notre architecture, les zones mémoires allouées dans la stack se remplissent dans le sens croissant des adresses (de 0..0H à F..FH) ce qui semble logique. Par contre, l'empilement sur la stack s'effectue dans le sens décroissant! C'est-à-dire que l'ESB originale est l'adresse la plus grande et que le sommet est 0..0H. De là naît la possibilité d'écraser des données vitales et d'avoir un buffer overflow.
En effet, si notre buffer se trouve dans la pile d'une sous-routine et si nous le remplissons jusqu'à dépasser sa taille allouée, nous allons écrire par-dessus les données qui se trouvent à la fin du buffer, c'est-à-dire les adresses qui ont été empilées précédemment : EBP, EIP... Une fois la routine terminée, le programme va dépiler EIP et sauter à cette adresse pour poursuivre son exécution. Le but est donc d'écraser EIP avec une adresse différente que nous pourrons utiliser pour accéder à une partie de code qui nous appartient. (par exemple le contenu du buffer)
Un problème à ce stade est de connaître l'adresse exacte de la stack (surtout sous Windows) pour pouvoir sauter dedans. On utilise généralement des astuces propres à chaque système (librairies, etc..) qui vont permettre -indirectement- d'atteindre notre stack et d'exécuter notre code. Cela nécessite un débogage intensif qui n'est pas à la portée de tout le monde...
Solutions et protection contre les buffer overflow
- Lors du développement : propreté du source (utiliser malloc/free le plus possible, utiliser les fonctions n comme strncpy pour vérifier les limites...), utilisation de librairies de développement spécialisée contre les buffers overflow (comme la défunte Libsafe d'Avayalabs)
- Utiliser des langages de programmation sécurisés : certains langages, comme Rust, Swift, ou Java, sont conçus pour éviter les buffers overflow grâce à des mécanismes de sécurité intégrés.
- Utiliser des logiciels spécialisés dans la vérification de code source, comme par exemple SonarQube, Qaudit ou Flawfinder.
- Auditer le programme compilé à l'aide d'outils tels que BFBTester.
- Appliquer le plus rapidement possible les patchs fournis par les développeurs.
- Fiabiliser l'OS pour qu'il ne soit pas vulnérable aux dépassement de tampon, par exemple : grsecurity pour Linux.
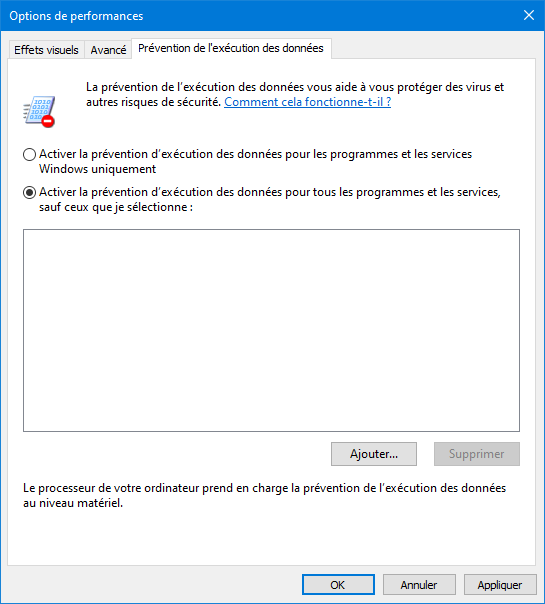
Exemple de protection de l'exécution de la zone de données de Windows 10. Encore faut-il l'activer comme ci-dessous. Pour cela, rechercher "Régler l’apparence et les performances de Windows" puis cliquer dans l'onglet "Prévention de l'exécution des données" :
SoGoodToBe et Arnaud Jacques, 04 Juin 2001 / 2020
Tags
Inscription à notre lettre d'information
Inscrivez-vous à notre lettre d'information pour vous tenir au courant de nos actualités et de nos dernières trouvailles.






© 2000-2026 - Tous droits réservés SecuriteInfo.com